ONYX
Compte rendu : Data pipeline vs Python V1
Dans le cadre du projet de migration des flux Slogia de Next vers Neowise, nous nous somme posés la question suivante : « Un script python peut-il être plus performant que les data pipelines d’Onyx ?». Pour y répondre, nous avons décidé de comparer les data pipelines à deux scripts pythons. Un premier script assez simple qui se contente de lire et d’écrire les données et un deuxième utilisant des threads et la technique du streaming. Nous avons testé ces trois méthodes sur des fichiers de différentes tailles contenant des données de type charactère, entier, date. Ces fichiers sont lus depuis un blob storage azure et sont stockés dans une base de données SQL SERVER. La mesure du temps d’exécution est basée sur une moyenne de 5 exécutions. Ces trois méthodes ont été exécuté depuis Onyx Neowise.
Remarque : les deux scripts python se trouvent en annexe.
Data File Information
| Nom du fichier | Nombre de lignes | Nombre de colonnes | Taille (en Mb) |
|---|---|---|---|
| CSV_with_5000row.csv | 5000 | 7 | 0.25 |
| CSV_with_50000row.csv | 50000 | 7 | 2.5 |
| CSV_with_100000row.csv | 100000 | 7 | 5.1 |
| CSV_with_500000row.csv | 500000 | 7 | 26.7 |
| CSV_with_1000000row.csv | 1000000 | 7 | 54.6 |
Data Pipeline
Pour les fichiers de moins de 30 Mo, le temps d'exécution est presque identique (environ 5 secondes), ce qui indique que le temps d'exécution du script des data pipelines est très court. La majeure partie du temps d'exécution est consacrée à l'orchestration. Pour un fichier de 0,25 Mo, le temps d'exécution est de 0,1 seconde, tandis que pour un fichier de 30 Mo, il est de 0,5 seconde. Cette différence de temps est facilement masquée par les 5 secondes en moyenne du temps d'orchestration. Une différence significative est observée pour le fichier de 50 Mo, avec un temps d'exécution de 11 secondes.
Script Python Classique
Contrairement aux data pipelines, le temps nécessaire à la lecture et à l'écriture du fichier CSV augmente de manière linéaire avec la taille du fichier. Cela suggère que le temps d'exécution des scripts est conséquent, et que le temps d'orchestration, qui est fixe, représente une part plus faible du temps d'exécution global. Les barres d'erreur ont également été calculées, mais en raison de la grande différence d'échelle des axes, elles ne sont pas visibles sur le graphique.
Script Python Streaming
Les résultats sont similaires au premier script Python. On observe cependant un temps d'exécution légèrement plus long.
Script Python Bulk
L'insertion en mode "bulk" améliore significativement le temps d'exécution. On observe des temps jusqu'à 3 fois plus courts que pour les autres scripts. Il est à noter que l'exécution en mode "bulk" nécessite l'utilisation de la bibliothèque "pyodbc", qui n'est pas compatible avec Onyx. Les scripts ont donc été exécutés en local. Pour obtenir des temps d'exécution comparables aux autres scripts, un délai de 10 secondes a été ajouté pour prendre en compte le temps d'orchestration et de lancement d'un script Python sous Onyx.
Script Python Bulk Streaming
Le streaming n'apporte pas d'amélioration significative en termes de temps d'exécution, même pour les scripts utilisant l'insertion en mode "bulk". Les mêmes remarques sur la compatibilité de la bibliothèque et le délai ajouté s'appliquent.
En conclusion, les data pipelines surpassent de loin les scripts Python en termes de temps d'exécution, quelle que soit la taille du fichier. L'insertion en mode "bulk" offre la meilleure amélioration, tandis que le streaming a un impact limité. Cependant, il est important de noter la compatibilité de la bibliothèque et le délai ajouté pour l'exécution des opérations en mode "bulk" sous Onyx.
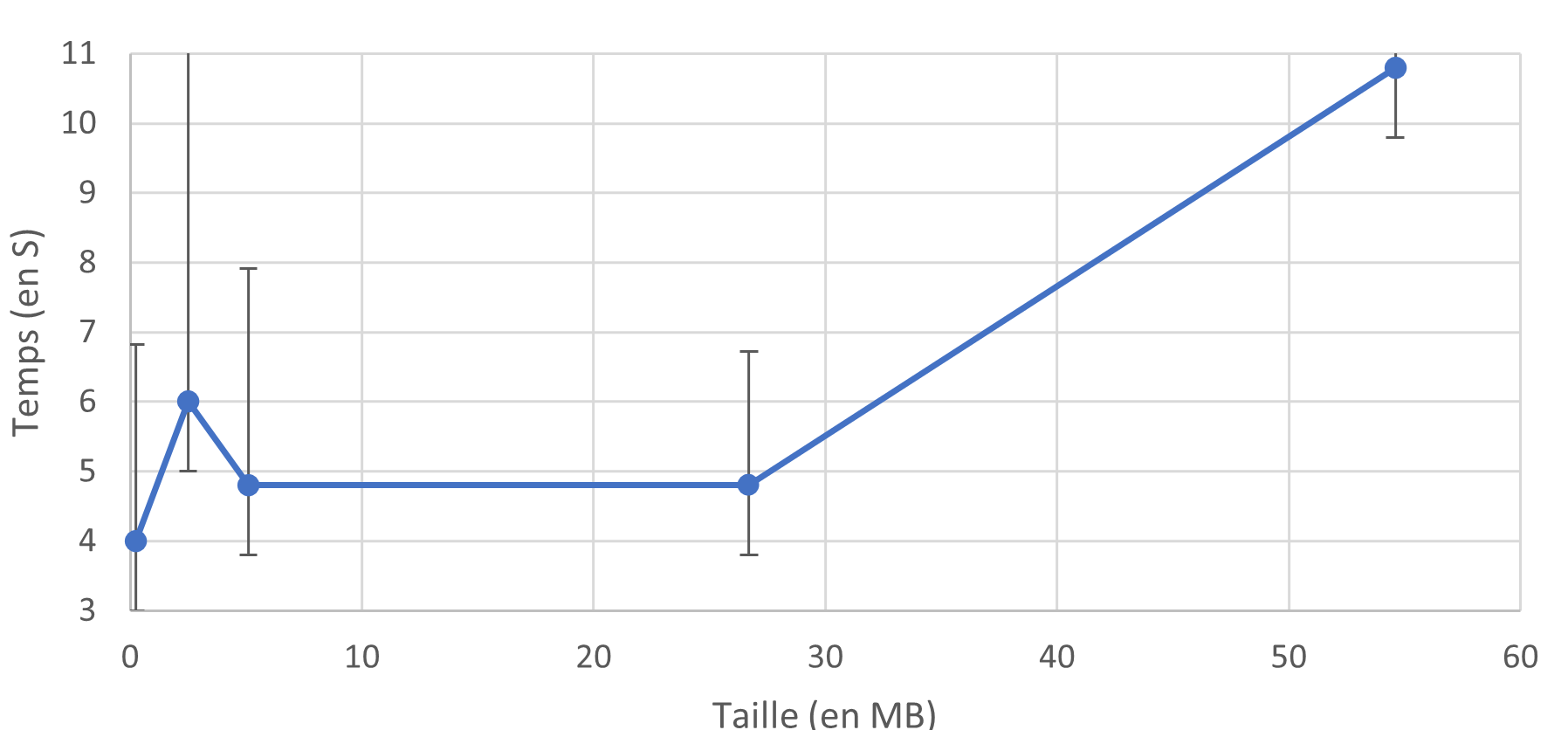
Temps d'éxécution du data pipeline en fonction de la taille du fichier
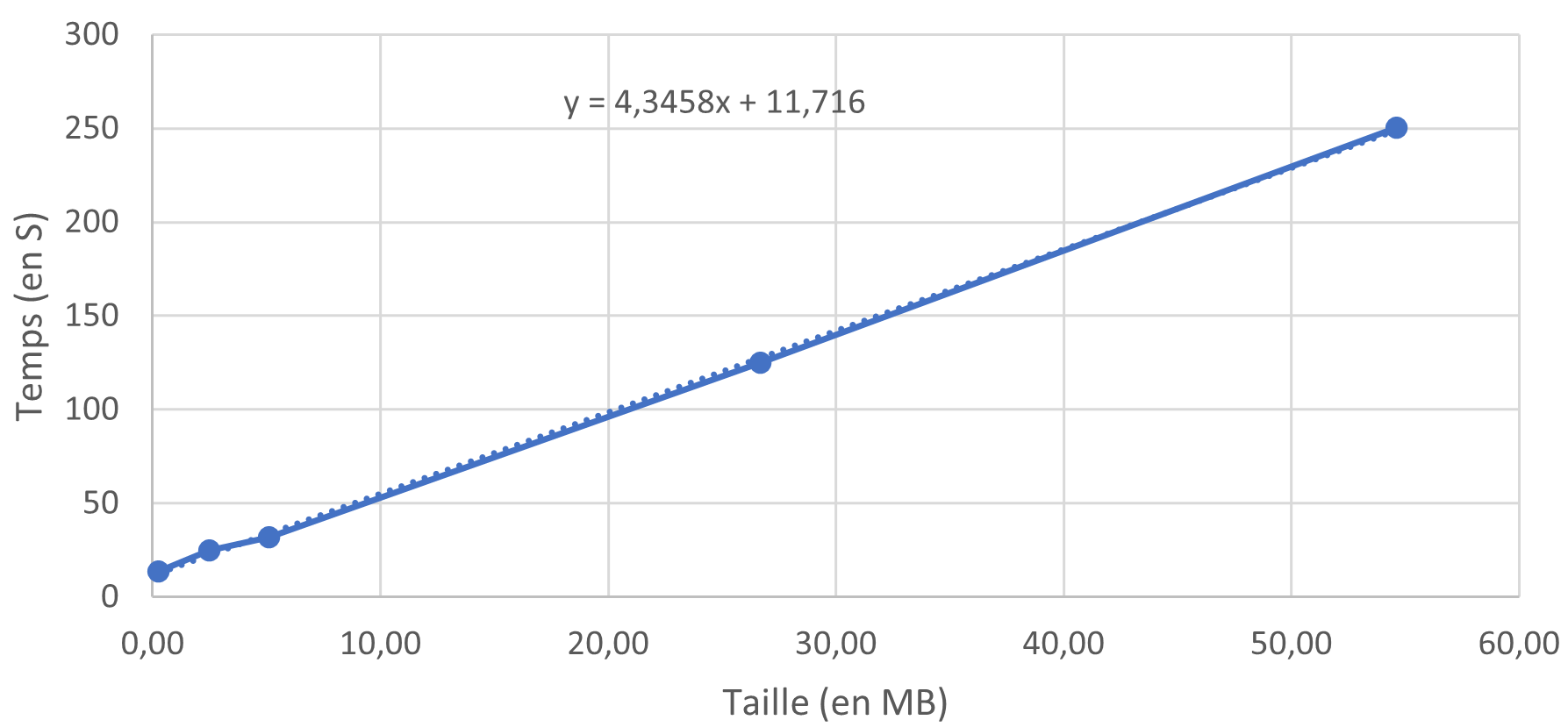
Temps d'éxécution du script python classique en fonction de la taille du fichier

Temps d'éxécution du script python streaming en fonction de la taille du fichier
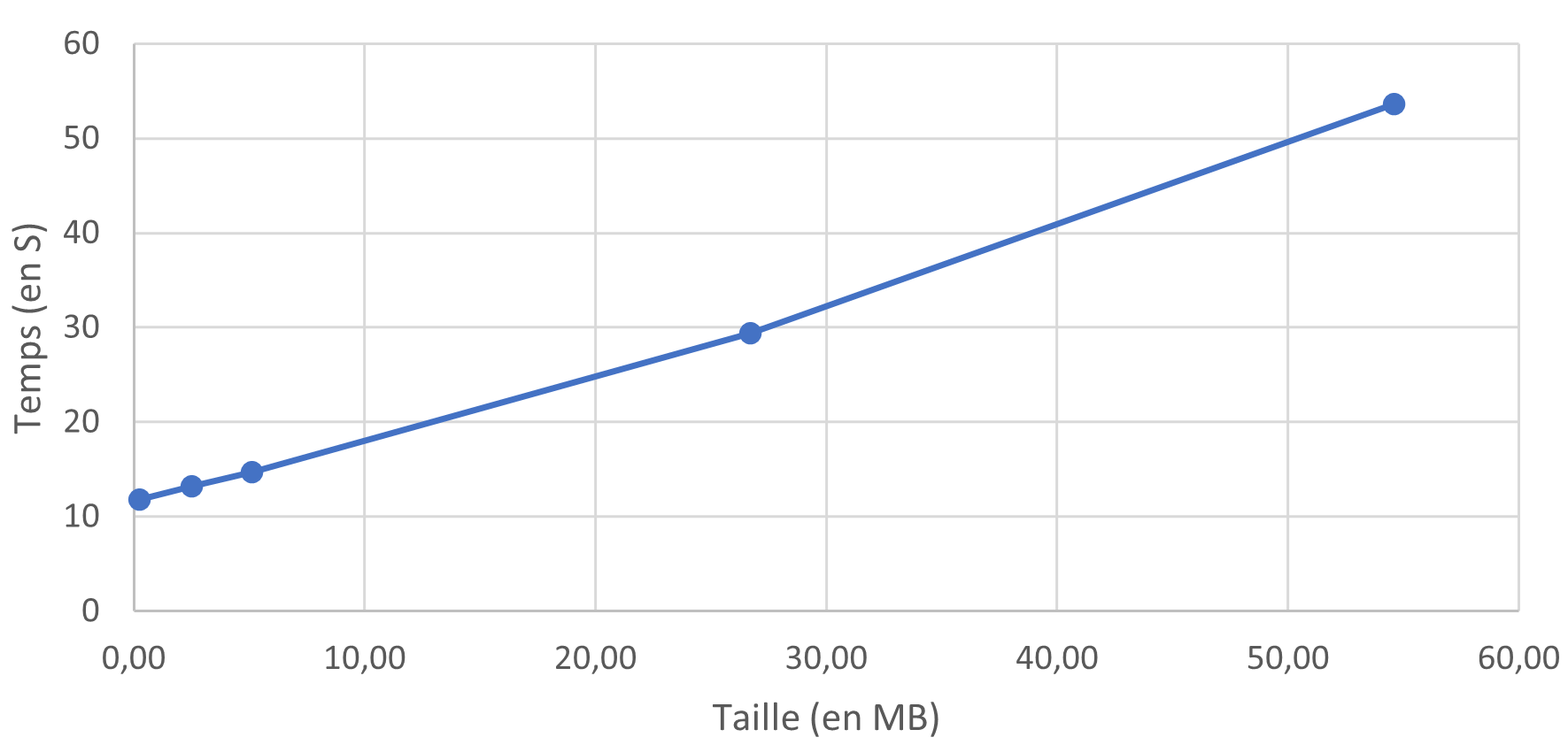
Temps d'éxécution du script bulk en fonction de la taille du fichier
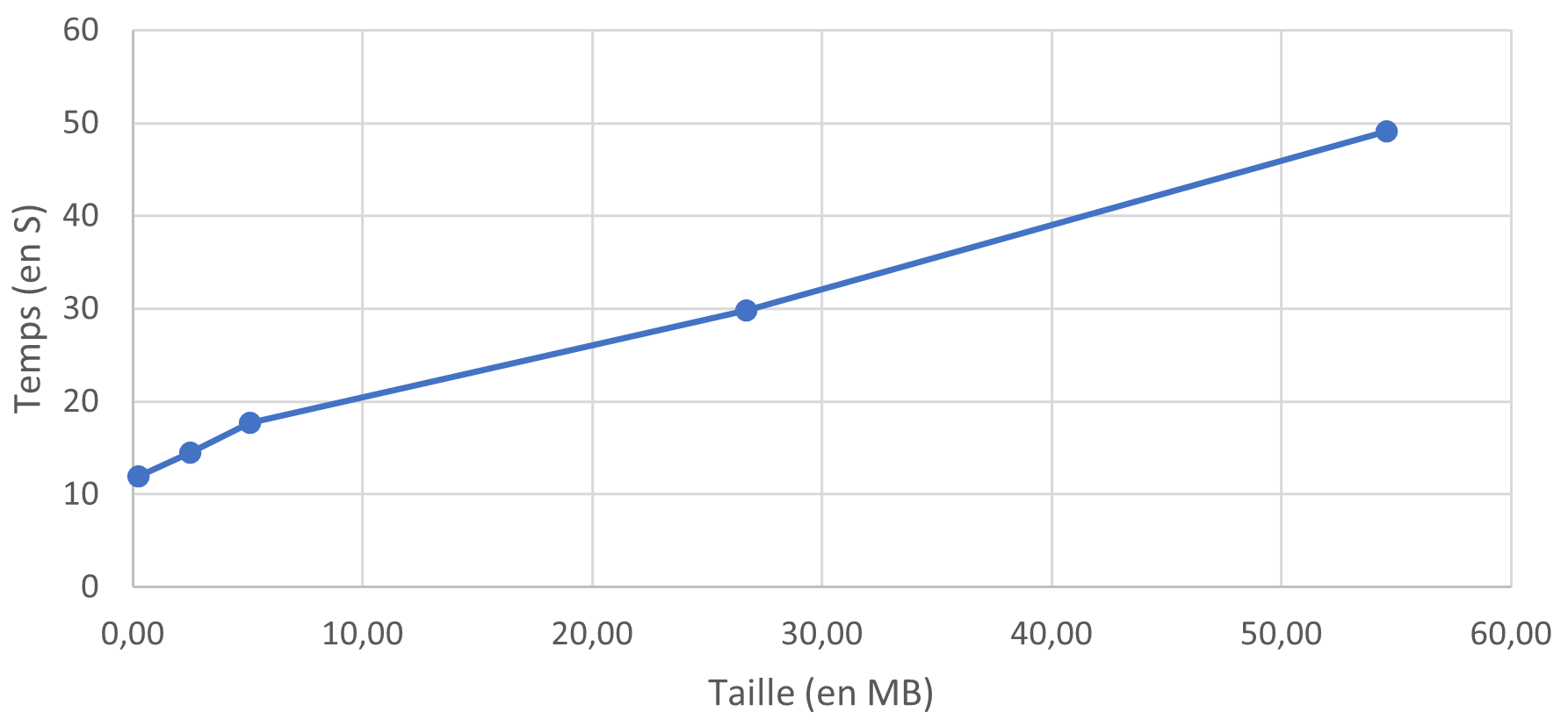
Temps d'éxécution du script bulk streaming en fonction de la taille du fichier
Comparaison entre temps d’orchestration et temps d’exécution du script (Python uniquement)
La section "Comparaison entre temps d’orchestration et temps d’exécution du script (Python uniquement)" présente les résultats pour les scripts Python classique et en streaming, ainsi que l'analyse comparative des différents procédés, à l'exclusion des data pipelines et des scripts utilisant l'insertion en mode "bulk".
Script Python Classique
Pour le script python classique, le temps d'orchestration, qui représente le temps nécessaire à l'organisation et à la coordination des tâches, occupe une proportion décroissante par rapport au temps global d'exécution du script. De manière surprenante, le temps d'orchestration diminue avec l'augmentation de la volumétrie des fichiers. Cela s'explique par le fait que les data pipelines volumineux ont été exécutés pendant la nuit, période de faible activité, afin de ne pas surcharger la base de données.
Script Python Streaming
Le script python en streaming présente des résultats similaires au script python classique.
Comparaison des différentes méthodes
Dans la partie "Comparaison des différentes méthodes", les temps d'exécution des différents procédés sont présentés, y compris les data pipelines, les scripts classiques, les scripts en streaming, les scripts avec insertion en mode "bulk" et les scripts avec insertion en mode "bulk" et streaming. Les écarts en secondes par rapport aux data pipelines sont également indiqués, ainsi que les écarts en pourcentage.
Il est remarquable que les data pipelines surpassent largement les scripts Python en termes de temps d'exécution, et cet écart se creuse davantage avec l'augmentation de la volumétrie des fichiers. Les scripts en mode "bulk" offrent la meilleure amélioration en termes de temps d'exécution, tandis que le streaming a un impact limité.
Pour comparison, Les temps d’exécution de tous les scripts python ont été augmenté de 5 secondes. De cette manière les scripts sont à égalités car un data pipeline Onyx nécessite en moyenne un temps d’orchestration de 5s.
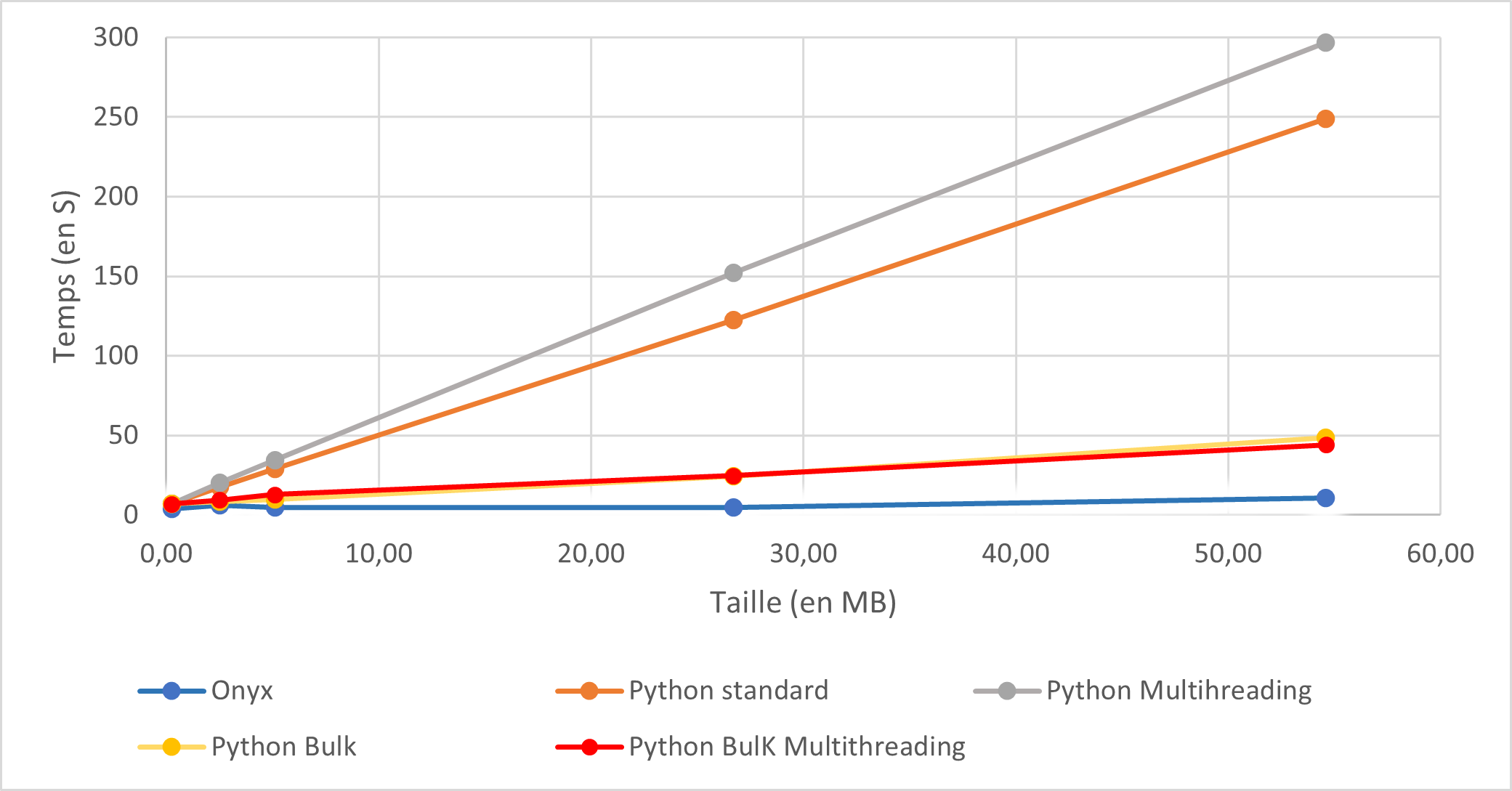
Comparaison du temps d'éxécution entre Onyx et Python
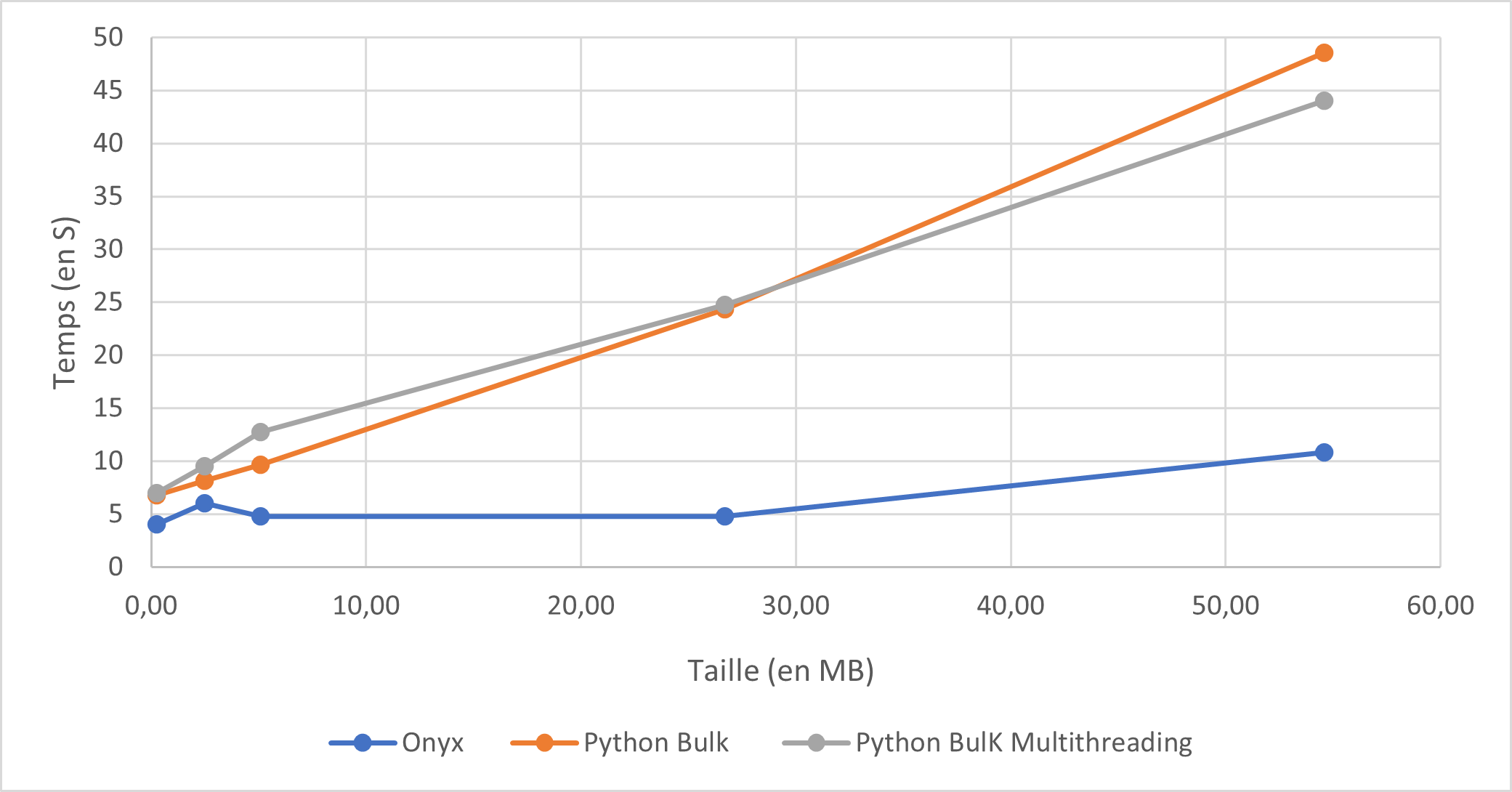
Comparaison du temps d'éxécution entre Onyx et Python (Bulk insert)
Conclusion
Les data pipelines sont de très loin meilleurs pour l’envoi d’un fichier csv vers une base de données que les scripts python, et ce, peu importe la volumétrie du fichier source. Même si on arrive à obtenir des performances tout à fait correctes avec du bulk insert, l’écart reste important. De plus, notre test s’arrête à l’exécution d’un fichier de 50Mo, on peut imaginer que cet écart continuera de s’accroitre avec l’augmentation de la volumétrie.